Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Join our daily and weekly newsletters for the latest updates and exclusive content in the industry’s leading AI coverage. Learn more
Two popular approaches to customize large language models (LLMS) for downstream tasks, subtle adjustment and learning in the context (ICL). One Last ResearchThe researchers at Google Deepmind and Stanford University examined the generalization of these two methods. They find that the ICL has more generalization (even if it comes to a higher calculation cost during inference. They offer a novel approach to get the best of both worlds.
Findings can help develop important decisions when building LLM applications for LLM applications for LLM applications.
Nice adjustment Teaches a pre-made LLM and treats a smaller, specialized database. It adjusts the internal settings of the model to teach new knowledge or skill. Learning in context (ICL), on the other hand, does not change the main parameters of the model. Instead, directly guide the LLM by submitting the examples of the desired assignment directly within the entry request. The model uses these examples to understand the new, similar query management.
The researchers set out to seriously compare the generalization of how to order new positions using these two methods. Imaginary family built “actual knowledge-controlled synthetic databases”, such as hierarchies of trees or fictional concepts.
To ensure that the model has tried the ability to learn new information, all nouns, adjectives and verbs have replaced any overlapping verbs with the information they encounter each other in advance.
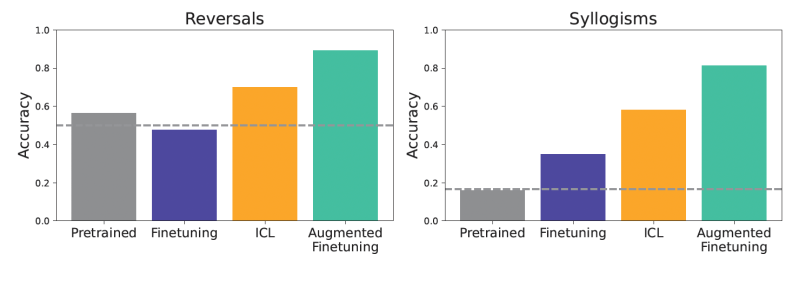
The models were then tested on various generalization problems. For example, a test is involved Simple reverse. A model “more dangerous than FEM GLON”, “What is less dangerous than FEMP” can this show the right result? Focused on another test Simple Sylogismsthe form of a logical discount. If “all glon glon yoomp” and “all Trumff Glon” can model “All Trumof’s YOMP”? In addition, to try a more nuanced concept, they used a more complicated “semantic structure” with a richer hierarchy of these current facts.
“How are our results, models, models, and a model for reverse substantiations, and a model of the owner of the infection and the property of the ownership of the author of the research scientist and the author of the author of the author of the author of the author of the author of the author of the author of the author and the author of the author of the author of the author of the author of the author and the author of the author of the author of the author of the author’s author.
To assess performance, researchers are beautifully regulated Twins 1.5 Flash In this database. For the ICL, before breaking the test questions, all training databases (or large subspers) have fed up to an instructional model.
The results showed that the information in the appropriate parameters caused better generalization than the standard subtle adjustment. Models that use ICL, were generally better in positions as they regularly make recommendations back or logical separations. Pre-made models, without delicate adjustment or ICL, show updates of the test data.
“One of the main trade is to consider the ICL not requiring subtle regulation (saving training costs), generally, because each use is expensive, the model provides additional context,” he said. “On the other hand, ICL tends to summarize better for the information and models we appreciate.”
Observation of Excells in ICL, researchers, researchers have a new method to improve subtle regulation: Add subtle results to subtle regulation data. The main idea is to use its own ICL capabilities of LLM to create more different and rich results, and then add these expanded patterns to the database used for subtle arrangements.
They investigated two basic information expansion strategies:
When the models are well adjusted in these expanded databases, the gains were significant. This expanded delicate regulation is not only standardized generalized generalized generalized generalized generalized, not only standard subtle adjustment, but also a flat ICL.

“For example, one of the company’s documents ‘XYZ is an internal tool for analyzing data,’ Our results, model ‘Which internal means are there for information analysis?’ It shows that it will be more effective in responding to related questions like lampinen.
This approach offers a way leading for enterprises. By investing in creating this ICL extended databases, developers can build beautiful regulated models that demonstrate stronger generalization.
This can lead to more powerful and reliable LLM applications in different, real-world entries without a sustainable result of incomplete time costs associated with instructions in a large context.
“Expanded subtle regulation will generally make the subtle regulation process more expensive, because it requires an additional step of the ICL to increase data,” said Lampinen. “Not combining additional value with improved generalization, regardless of the use of the model, each time the model is used to use ICL every time the model is used.”
Lampinen said that in different parameters should be more research to see how the components are needed, the findings and developers can only want to investigate subtle adjustments in the uninterrupted performance of subtle adjustment.
“As a result, we hope that this work will contribute to the practicalization of adaptation to the basic models and their low streams and contribute to the science of generalization.
