Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Join our daily and weekly newsletters for the latest updates and exclusive content in the industry’s leading AI coverage. Learn more
All AI landscapes, then a little-known Chinese EU Starter DeepSeek (Hong Kong-based quantitative analysis firm management of Hong Kong capital) in January 2025) Started the Reasoning Model of Strong Open Source Language DeepSeek R1 To the world, which is giants like meta, to the world.
As the use of DEEPLEK, as rapidly spreading between researchers and enterprises, Meta has been reported to be sent to panic mode After learning that this new R1 model prepares for a part of many leading models, several million dollars pays a few million dollars and a part of the AI team leaders.
All generative AI strategies of Meta, to this point, for this point, the LLAMA brand and companies “Llama” LLAMA “LLAM” LLAM “LLAM” “LLAM” “If the user will contact meta for the specific paid license conditions). However, the amazingly good performance on the smallest budget of R1 has shaken the company’s management and forced some kind of settlement with the latest version of Llama, 3.3It was still outdated in December 2024 a month ago.
Now we know the fruits of this effort: Today, Meta founder and CEO Mark Zuckerberg took to Instagram to announce a New Llama 4 Row ModelsWith two of them – 400 billion parametric zlama 4 maverick and 109 billion parameter Llama 4 Scout – Today is available today to download or delicate it for developers lllama.com and AI code sharing community Hug face.
Massive 2 trillion parameter Llama 4 Behemoth is also in advance today, About Meta Blog Releases He still said he was taught and gave no sign about it could be released. (It should be noted that the parameters refers to the patterns that manage the model of the model and are generally more powerful and complex around a more powerful and complex model.)
The feature of these models is a title feature, all multimodal and therefore prepared and therefore accepting and creating text, video and image (HOUGH Audio).
The other, in an incredibly long context Windows – Llama 4 Maverick and Llama 4 for 1 million Tokens and Llama 4 scouts are equivalent to 1000 and 15.000 pages, all of them are equivalent to 10000 and 15,000. This can take a user, 7500-page valuable text or download or paste text up to 7500 pages and get so much from the scout, drugs, science, engineering, mathematics, etc.
So far, what else have we learned about this release:
Three models “use the” architectural approach “of experts (MOE) From Openai to become popular in the previous model and MistralMany small models in different positions, topics and media formats (experts “) are said to be a combined whole model.
LLA 4 blogs as notes:
As a result, all parameters are stored in memory, only one sub part of the total parameters is activated when serving these models. This improves the effectiveness of fruitless efficiency by reducing model service costs and can work in one of the delay-llama 4 maverick [Nvidia] HOW H100 DGX Hosts with easy placement or distributed results for maximum efficiency.
Both Scout and Maverick, for Hosting, have been declared valuable steps for no hosting or special meta infrastructure. Instead, Meta Whatsapp focuses on distribution through open download and integration with Meta AI on Messenger, Instagram and Internet.
Meta evaluates the end value for 4 maverick for 4 maverick, $ 0.19 to $ 0.19 / 1 to $ 0.49 / 1 to $ 0.49). This is cheaper than property models such as GPT-4o, estimated to cost $ 4.38 per million token.
All three Llama 4 model-especially designed to solve the problem of maverick and behemoth-fine, coding and step-by-step problem.
Instead, more “classic,” are designed to compete more with multimodal models like “classic,” beliefs and depexicat-in v3 with non-reasonable LLS and multimodal models – exclude 4 behemoth is doing DeepSseek seems to be threatening to R1 (more about it below!)
In addition, special post-training pipelines aimed at increasing meta and justification for Llama 4:
Metap is a special interest in the model, because the model increases exercise efficiency, to determine hyperparameter and then acquire many other model types.
As my VentureBeat Falleague and LLM Specialist Ben Dickson opened a new metap technique: “It can make a lot of time and money. It means that they are experiments in smaller models for large-scale ones.”
This is 32K GPUS and FP8 accuracy, 390 TFLOPS / GPU, which uses 390 GPUs and FP8 from 30 trillion token, it is as great as a 390 TFOP / GPU than 390 TFOP / GPU.
In other words, researchers can practice how to move the model and apply the larger and smaller version of this model and in the form of different media.
In itself Announcement Video in Instagram (Meta subsidiary Mark Zuckerberg, the company’s “Objective” “The goal is to build a world-leading AI, built an open source, and in general, I think open source AI’s leading models and start with Lama 4.”
Naming Meta Blog, Llama 4 Scout, “Blog Post, the best multimodal model in the world, is a clearly careful statement In class and stronger than the previous generation of Lama models “(I added emphasis on me).
In other words, these are very powerful models, their parameter is near the stack of stacks compared to others in the size class, but definitely not set new performance notes. Nevertheless, Meta, the new Llama beat the beat of 4 families, and among themselves to play a new Llama beat:



Of course, DeepSeek R1, Openai’s “O” series (GPT-4O), has a fundamental heavy models like Gemini 2.0 and Klod Sonnet.
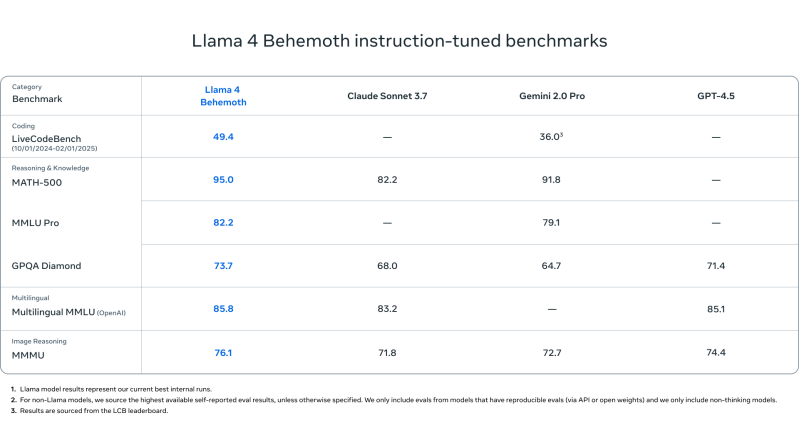
Using the highest parametric model and compare with 4 behemoth and intial DeepSEEK R1 Issue Schedule Llama 4 behemoth collected for R1-32B and Openai O1 models:
| Calister | Llama 4 behemoth | DeepSeek R1 | Openai O1-1217 |
|---|---|---|---|
| Math-500 | 95.0 | 97.3 | 96.4 |
| GPGA DEST | 73.7 | 71.5 | 75.7 |
| Mmlu | 82.2 | 90.8 | 91.8 |
What can we do?
Takeaway: DeepSeek R1 and Openai O1 O1 is in a few sizes, in a highly competitive or classroom leadership panel in the Llama 4 Behemoth, or in the nearby leadership panel.
META also helps the model adaptation and safety, developers to introduce tools such as Llama Guard, Start, Start-I and Kibbie-Serring, and help develop generation agent test for the automated red-team.
The company also claims that there is a significant improvement on “political bias” on the Llama 4 and says “specifically [leading LLMs] As for the political and social issues of historically discussed, he leaned the left when he said, “It is better to deprive the right wing from the right wing.” Zuckerberg’s Republican US President Donald J. Trump’s hugs and the party after the 2024 elections.
Methane Llama 4 models bring the effectiveness, openness and high-level performance between multimodal and reasoning positions.
With Scout and Maverick, it is now open and behemoth is placed in the most modern teacher model, open, anthropic, DeepSearch, open, anthropical, DeepSEEK and Google to offer a competitive open alternative to the highest level property models.
Enterprise-scale assistants, AI research pipelines or long-term contextual analytical instruments, Llama 4 offers high performance options – a clear direction for the first design is clearly oriented.
