Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Join a reliable event by enterprise leaders in about two decades. VB Transform, Real Enterprise AI strategy brings together people who build. Learn more
Chinese EU starting miniMax is probably known for the best in the West Oh video model hailuoannounced the latest large language model, Minimax-M1 – And in great news for businesses and developers, completely Open Source under the Apache 2.0 licenseMeaning businesses can accept it and use it for commercial applications and change it to your liking without restriction or payment.
M1 is an open suggestion that prescribes new standards in the use of long-term justification, agent tool and effective calculation performance. Today is available in AI code sharing society Hug face and Microsoft’s opponent code sharing community githubThe first issue of the name “Minimaxweek” is expected from the company’s social account X – subsequent product ads.
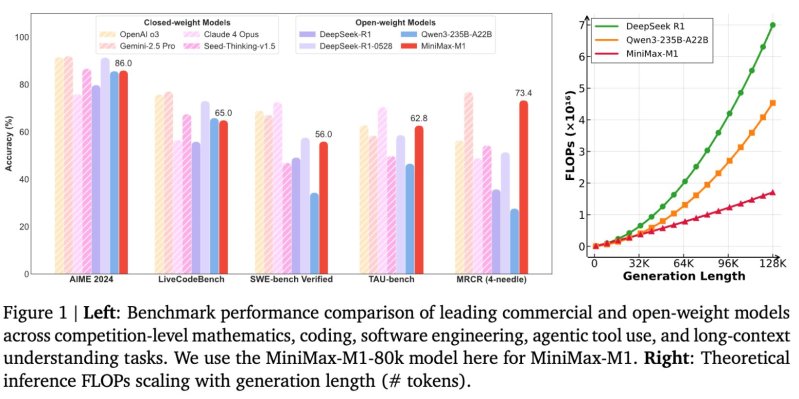
Minimax-M1 distinguishes 1 million signs with a context window and in exit is different from 80,000 verses, it places it as one of the most widespread models for long-term reasoning tasks.
In large language models, the “Context Window” (LLMS) refers to the maximum number of the model, which can process the model at a time, including a moment and exit. Tokens are text units that can include all words, parts, punctuation or code characters. These verses become numerical vectors that use the model to represent and manipulate the meaning of the patterns of the model. These are essentially, the mother tongue of the LLM.
For comparison, Openai’s GPT-4O Only 128,000 Token has a context window – enough to exchange about the information of a novel The only and forward interaction between the user and the model. MiniMax-M1 can exchange 1 million token with 1 million collection or information of the book series. Google Gemini 2.5 Pro offers a Token context of 1 millionHe was also reported in the works by 2 million windows.
But M1 has another cunning: developed using the reinforcement learning in innovative, skillful, highly efficient technology. The model is taught using a hybrid mixture (MOE) architecture, which is a lightning focus mechanism designed to reduce the cost of inferred costs.
According to the technical report, Minimax-M1 consumes only 25% of the required floating point operations DeepSeek R1 100,000 tokens in a generation length.
The model applies to two options-minimax-m1-40k and minimax-m1-80k-m1-80k -i “thinking budgets” or exit lengths.
The company’s previous minimax-text-01 of the company is based and includes 456 billion parameters, each of which includes 45.9 billion parameters of 45.9 billion per Token.
The sustainable feature of the release is the model of the model. Minimax says that the M1 model is a large-scale strengthening learning (RL) in this domain, in a rarely effective effectiveness, the total cost is $ 534,700.
This efficiency is transferred to a special RL algorithm called Hybrid focus design, which helps the hybrid focus design, which helps to help face the renovation of traits and scales.
This is an amazingly “cheap” amount for a frontist LLM because as AS taught the Hit R1 justification model The price of $ 5-6 million was reported‘The training value of one of the GPT-4 was now more than a two-year-old model – was He said it was $ 100 million. This expense uses the price of graphic processing sections (primarily, primarily, primarily, per capita of $ 20,000-2,000 or more modules, which are required to constantly manage these chips in large-scale information centers.
Minimax-M1, developed thinking, software engineering and tool used a number of criteria, which tested the ability to use.

In 2024, a math competition benchmark, 86.0% accuracy of the M1-80K model. It also provides strong performance in coding and long-term positions, achievements:

These results are ahead of other open opponents such as DeepSeek-R1 and other open opponents such as Qwen3-23b-a22b in several sophisticated tasks.
Indoor weight models such as Openai O3 and Gemini 2.5 Pro can still be obtained in freely under the Apache-2.0 license, which is still coinciding some criteria.
Minimax for placement, provides VLLM, referring to the optimization of great model workloads, memory efficiency and bulk survey. The company also provides placement options using the Transformers Library.
MiniMAX-M1, structured function includes challenging capabilities and packets online search, video and image, with a chatBot API containing speech synthesis and sound cloning tools. These features are aimed at supporting a wider agent behavior in real world applications.
The open access to Minimax-M1, long-term opportunities and calculation efficiency, solves a number of repetitive problems for technical professionals responsible for the scale of AI systems.
The LLMS for engineering is responsible for the full life of the LMS – such as model performance optimize and placement in tight times – minimax-M1 offers a lower operating price when supporting advanced thinking tasks. The long context window can significantly reduce pre-processing efforts for businesses or entry data, or hundreds of thousands of months of landing.
The AI orchestra supports easier integration into existing infrastructure for subtle and placement skills using built-in tools as VLLM or transformers for pipelines. Hybrid-focusing architecture can help simplify scaling strategies and offers high opportunities for internal copylots or agent based systems in multi-step and software engineering benchmarks.
The teams responsible for the protection of the information platform, effective, expandable infrastructure can benefit from the support of the M1 with a structured function and automated pipelines. Its open source nature allows teams to make the stack without locking the performance without locking.
The safety device can find a value that assesses the value of high-level model, high-capacity model of high-level model, which is incredibly transferred to the transfer of sensitive data to third party end points.
Together, Minimax-M1 provides a flexible choice for organizations who want to practice or scalt the expenses, while driving expenses and escaping property restrictions.
Focus signals focus on direction of minimax practical, scale AI models. Combining open access with advanced architectural and calculation efficiency, Minimax-M1 can serve as a basic model for generation applications that require both fundamental depth and long-term entry concept.
We will follow other releases of minimax during the week. I’m galent!
