Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Want smarter ideas in your inbox? Sign up for our weekly newsletters to get what is important for businesses, information and security leaders. Subscribe now
Mistral Today, the voice AI, a voice AI, left an open source sound model that can afford such a sound AI Onelabs and Hume aiThe company says, the gap between speech recognition models and more open, but tendencies.
The Mistral is available in the Voxtral, 24B parameter version and 3B option to release under an Apache 2.0 license. The larger model, a small version is designed for applications on a scale when working for local and outdoor use.
“The sound allows you to share and associate your work, sharing and coordinate these ideas before writing the first interface of mankind. Blog Post. “Today’s systems remain limited, unsafe, property and very fragile for the use of real world. It requires exceptional transcription, deep concept, multilingual fluency and clear, flexible placement.”
Available in the Voxtral Mistral API and has only one transcription on the website. The models are also accessible through Le Chat with the Mistral chat platform.
AI impact series returns to San Francisco “€ 5 August
The next stage of AI is you ready here?
Take your place now – Location is limited: https://bit.ly/3guplf
The Mistral said the EU was “the choice between two trade,” some open source automated speech recognition models were often exposed to a limited semantic concept. Again, indoor models with a strong language concept come to a high price.
The company said that VoxTral “” The most modern precision and native semantic understanding of the price of comparable APIs is the most modern accuracy and native semantic understanding. ”
VoxTral can listen and transcribe the audio concept of up to 30 minutes or 40 minutes in the 32K Token context. The model offers generalizations that can meet the questions based on the sound content and generally create generalizations without switching to a mode. Users can lead to features and API calls based on negotiation instructions.
The model is based on small 3.1 of the Mistral. Supports multiple languages and can automatically detect languages like English, Spanish, French, Portuguese, Indian, German, Italian and Dutch.
Mistral, including private placement, including special placement features, so the organization’s model can be integrated into their ecosystems. These features include a priority to special subtle regulation and engineering sources for engineering sources for customers who need to integrate VoxTral into work flows.
Talk Recognition AI is now available on many platforms today. Users can talk to Chatgpt and read the platform written instructions similar. As fast food chains White tower was placed Storm Their driver has been sustainable to their services and onstand To improve the multimodal platform. Open source space also offers strong options. Nari laboratoriesa start, left open source speech The model in April. But some of these services can be very expensive.
Transcription services such as Very and Read.ai Now they can raise themselves to meet, summarize, and even warn, according to the objects that move users. Many online video meeting platforms are not only transcruped, Also Speech AI and Agentic AItogether with Google Meetings that allow users who use the gem. As an ordinary user of voice transcription services, the recognition of the speech is not perfect, but I can say that it has improved.
Mistral stated that Voxtral has existing sound models, including existing sound models OpenWhisper, twins 2.5 leap and written from Elevenlab. Voxtral presented fewer word errors than whispering the best automatic speech recognition model now.
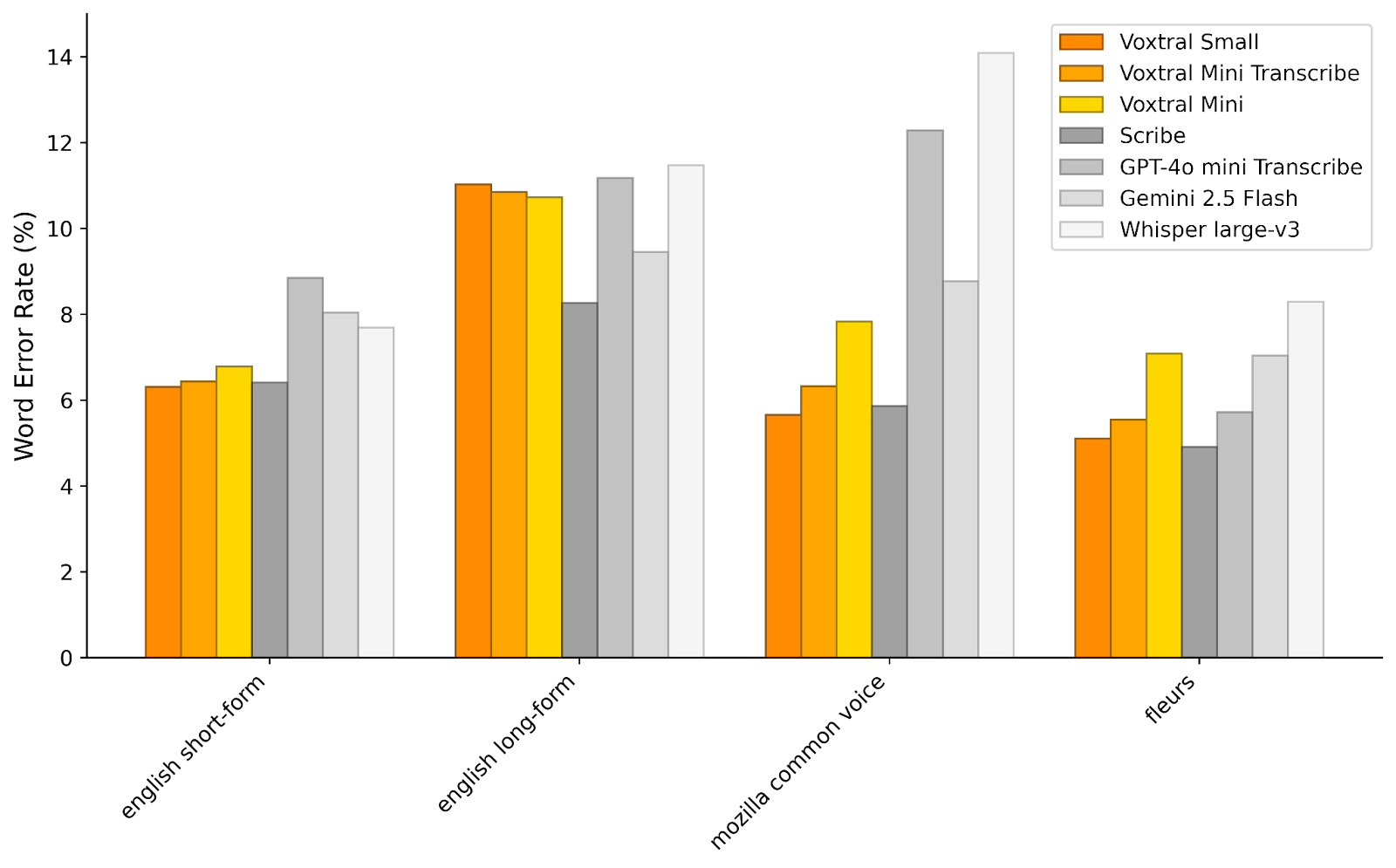
In terms of voice concept, compete with the voxtral small “GPT-4O-mini and Gemini 2.5, 2.5 flew 2.5 in all positions in the translation of speech.”
Since the announcement of the voxtral, social media users said they expect an open source speech model that may suit the whisper.
Mistral, Voxtral said it would be available at 0.001 per minute.
